
TL;DR: You can include one data file in another by adding this file to your _plugin directory: read_data_file_with_liquid.rb
I recently designed the website for one of my labs. After a lot of back and forth, I decided to build the site in Jekyll. Jekyll is a framework for building static websites. It has a lot of the same advantages of dynamic site frameworks like Ruby-on-Rails, except that Jekyll doesn’t do any database accesses or page construction every time a new user views the site. Instead Jekyll generates a bunch of HTML files one time and those can be served unchanged from your server forever until you decide to change the content. I like Jekyll because it allows a significant amount of customization while remaining relatively simple to create and deploy. As with most technology that’s easy to pick up and use, it can become increasingly difficult to use as the task becomes more and more complicated. This is a story about how feature creep painted me into a corner, and a description of the hack I used to fix it. Hopefully this can serve as a warning to others, and potentially give them an out if they need it.
One view, one data store
The initial design of the site included a few prose-only pages and a “people” page to list all the members of the lab. Jekyll has the ability to build pages backed by data stored in various formats like YAML, JSON, or CSV. This data feature was an obvious way to factor out a lot of the repetition that would normally be required in a page that has dozens of identically formatted entries. The way it works is that you create a YAML (or JSON or CSV) file with some information. Let’s call it people.yml:
people:
- name: Dan
spirit_animal: Otter
- name: Lois
spirit_animal: Penguin
And then you can build an HTML (or Markdown) page with templating to automatically populate the page with the data from your YAML file:
{% for person in site.data.people.people %}
<div class="person" id="">
<div class="name"></div>
<div class="spirit_animal"></div>
</div>
{% endfor %}This will make an HTML page with two person divs, each populated with the data from the two people in people.yml file. So far so good. We’ve got a nice webpage with no duplication of logic and a good separation of concerns.
Two views, two data stores
As time went on, the demands of the project expanded and we needed to add a projects page to the site. No problem, just add a second data file and second view, projects.yml and projects.html respectively. Here’s what projects.yml might look like:
projects:
- name: Mercator
features: Cylindricality
- name: Armadillo
features: Compromise
So far everything was still fine, but it was about to get wacky. The next requirement was that every project link to every person who works on it, and every person link back to every project they work on. The simplest way to do this is by entering the data by hand:
projects:
- name: Mercator
features: Cylindricallity
people:
- name: Dan #
spirit_animal: Otter #
- name: Armadillo
features: Compromise
people:
- name: Dan #
spirit_animal: Otter #
- name: Lois #
spirit_animal: Penguin #
At this point problems were starting to emerge.
Now each person’s information needs to be entered in multiple places.
Once in people.yml, and several times in project.yml for every project that person works on.
This is a problem because every time a person’s information changes, we need to update that data in arbitrarily many places.
To help mitigate this problem, YAML provides anchors and references (notated with & and * respectively).
These features allow you to define data in one place and reuse it in other places without having to copy-paste all of the data.
people:
- &dan #
name: Dan
spirit_animal: Otter
- &lois #
name: Lois
spirit_animal: Penguin
projects:
- name: Mercator
features: Cylindricallity
people:
- *dan #
- name: Armadillo
features: Compromise
people:
- *dan #
- *lois #
One of the limitations of anchors and references, however, is that they only work within a single file. Up until this point the duplication was reduced to just having to define each type of information in each file, which for only two files is acceptable.
But of course, requirements continued to grow. We suddenly needed two new pages, one for publications and one for press. And there needed to be links between both of them and the project and people pages. Under this scheme, most of the of data needed to be copy-pasted between 4 different files, for a total of 14 datastructures which all need to be consistent with each other.
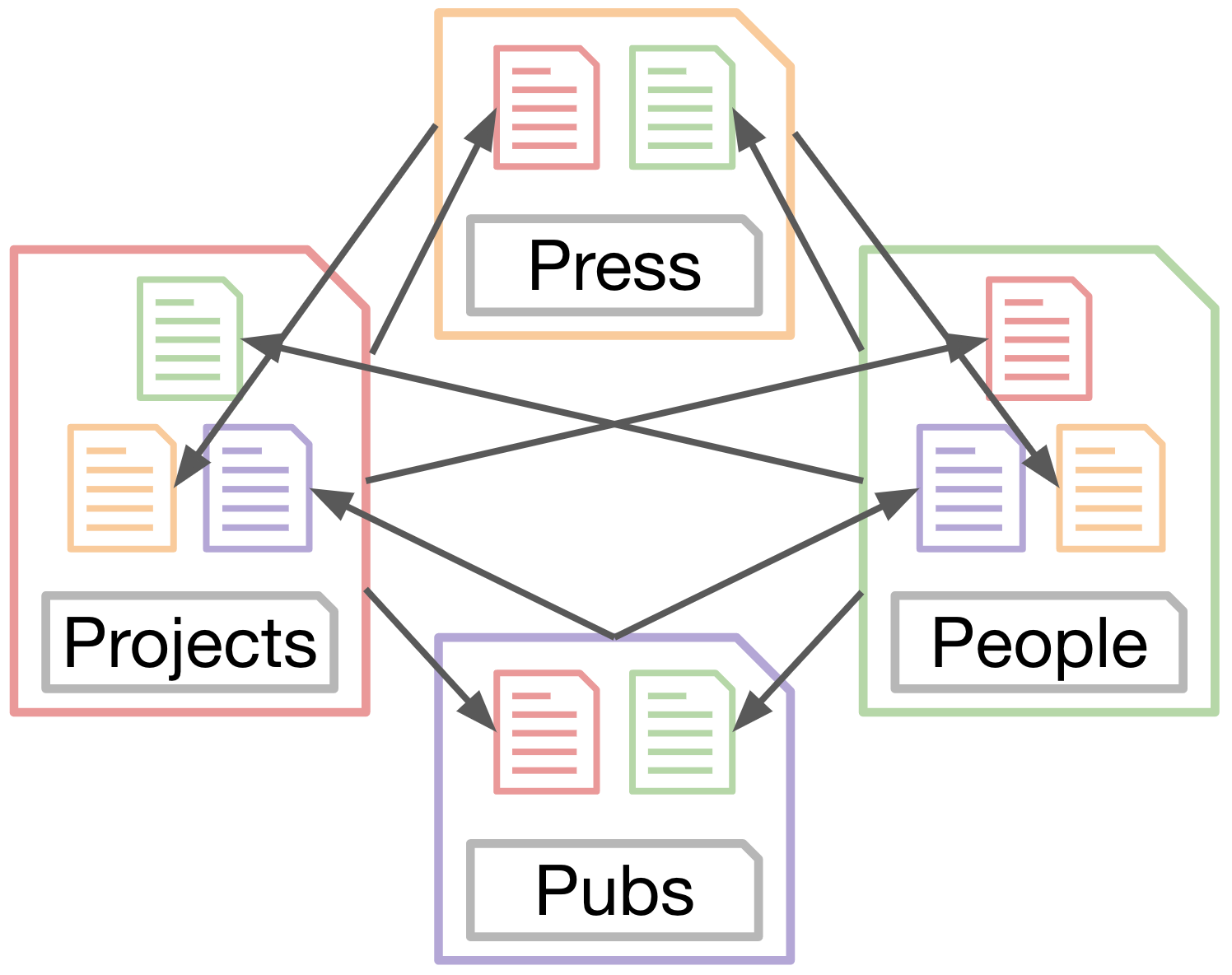
Uber-YAML
The only way to still leverage anchors and references between all 4 files even though anchors are only visible in the files in which they are defined was to merge all files together into a singular uber-yml file that contained all the data. There are several drawbacks to this method. Firstly, the singular file becomes very large. In our case the uber-yml was well over 2000 lines, all of which need to be ordered and indented correctly. Secondly, anchors are only visible to references below them, which means that data can’t be separated into groups. Ideally the top of the file would have definitions for all the people, followed by a section that defined all the groups. Instead, if the first group describes each of the projects, then each person must be defined immediately inside the first project they’re a part of.
projects:
- &mercator #
name: Mercator
features: Cylindricallity
people:
- &dan #
name: Dan
spirit_animal: Otter
projects:
- *mercator
- &armadillo #
name: Armadillo
features: Compromise
people:
- *dan
- &lois #
name: Lois
spirit_animal: Penguin
projects:
- *armadillo
- *armadillo #
people:
- *dan
- *lois
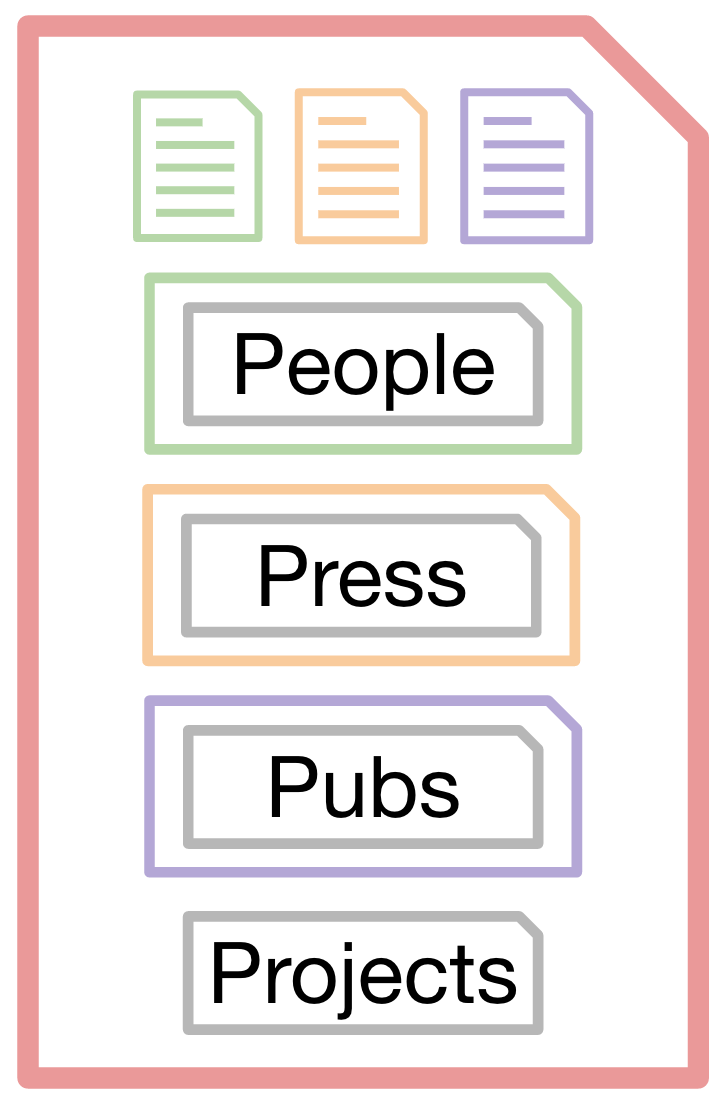
Solution
So, the ideal solution would have the following properties:
- DRY - (don’t repeat yourself) each model should be defined only once.
- Grouped - all similar data should be defined in the same format next to each other.
- Separated - different data should be defined in different places.
Each of the Jekyll data modelling methods methods above violates at least one of these ideals.
The way most full blown programming languages solve this problem is with an inclusion system.
You have one file that contains common definitions that can be included in every file that needs it.
The more complicated inclusion systems (for example in Clojure) set up modules and namespaces so that complicated dependency graphs can be navigated efficiently.
A simpler inclusion system (like the C preprocessor) simply injects the text of one file into another.
But it turns out that Jekyll already has a system like this built in, inside Liquid.
Among many other features, Liquid has the
{% include %}
_plugins/read_data_file_with_liquid.rb
# Treat every _data file as liquid.
# This allows us to include YAML files in other YAML files.
module Jekyll
# Monkey patch Jekyll::DataReader::read_data_file with our own implementation
class DataReader
def read_data_file_with_liquid(path)
begin
dir = File.dirname(path)
filename = File.basename(path)
# If there are multiple sites assume we're
# the most recent since we're just starting up
site = Jekyll.sites.last
content = File.read(site.in_source_dir(dir, filename))
template = Liquid::Template.parse(content)
context = Liquid::Context.new({}, {}, { :site => site })
rendered = template.render(context)
# Write the post-liquid-rendered file to a temporary file.
# read_data_file parses the name of the file to use as its
# variable name in site.data so it's important to make the
# temp file name match the original file name.
Dir.mktmpdir do |tmp_dir|
tmp_path = File.join(tmp_dir, filename)
File.write(tmp_path, rendered)
read_data_file_without_liquid(tmp_path)
end
rescue => e
Jekyll.logger.warn(
"[SSL-specific] Error parsing data files " +
"for Liquid content at file #{path}: #{e.message}")
end
end
# Make our function overwrite the existing read_data_file function
# but keep the ability to still call back to the original
alias_method :read_data_file_without_liquid, :read_data_file
alias_method :read_data_file, :read_data_file_with_liquid
end
endThis allows us to directly include one YAML file into another. For example:
_data/projects.yml
{% include_relative _data/people.yml %}
projects:
- name: Mercator
features: Cylindricallity
people:
- *dan #
- name: Armadillo
features: Compromise
people:
- *dan #
- *lois #

But when we go to reference projects from people the whole system breaks down. Suddenly, since all liquid is doing is retrieving the text of one file and putting it into the other, but treating both as liquid, there’s an infinite loop.
_data/people.yml
{% include_relative _data/projects.yml %}
people:
- &dan #
name: Dan
spirit_animal: Otter
projects:
- *mercator #
- *armadillo #
- &lois #
name: Lois
spirit_animal: Penguin
projects:
- *armadillo #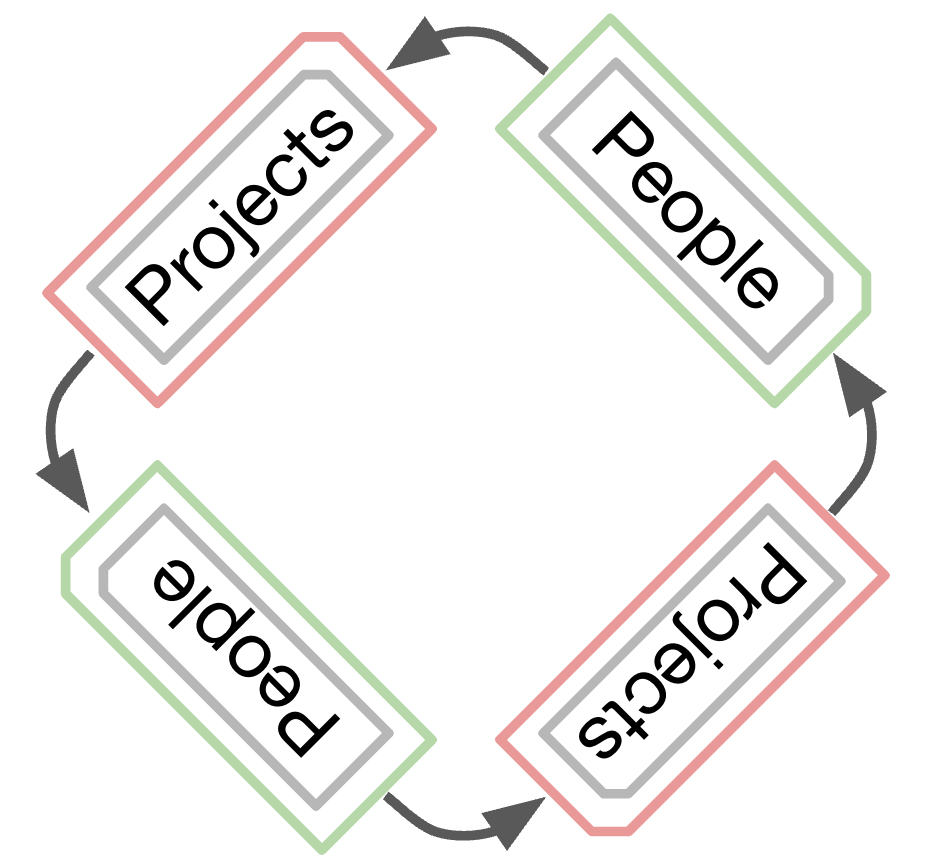
The canonical solution for this, used in systems like C’s preprocessor is to define a variable upon first inclusion.
Upon subsequent calls to the include function, if the variable is defined the file isn’t included.
In C this is accomplished with the #ifdef directive. In Liquid, we can pass variables to included pages.
_data/people.yml
{% unless include.included %}
{% include_relative _data/projects.yml included=true %}
{% endunless %}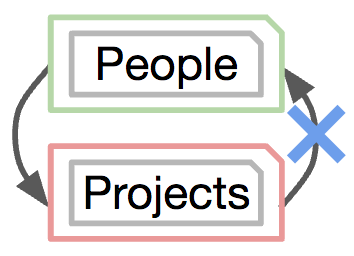
This solution, while technically sound, is somewhat annoying to have to place atop each of your data files. Instead it can be encapuslated inside a plugin for easy consumption.
_plugins/read_data_file_with_liquid.rb
# Only include the given file one time (in this call tree)
# Useful for files that include files that include the original file
module Jekyll
module Tags
class IncludeRelativeOnceTag < IncludeRelativeTag
# Create a flag that indicates we're already 1 level
# deep in the inclusion, and don't go any farther down
SENTINEL = 'included_relative_once'
def render(context)
context.stack do
unless context[SENTINEL]
context[SENTINEL] = true
super(context)
end
end
end
end
end
end
Liquid::Template.register_tag("include_relative_once", Jekyll::Tags::IncludeRelativeOnceTag)Then each file can include others with a single a command.
{% include_relative_once _data/projects.yml %}With all these pieces in place, each file can reference each other file. It’s achieved simply, with only one extra line of code required. There’s no reorganization of the data required. All similar data is grouped together, and kept in separate files from other types of data.
There are a couple drawbacks to this method:
- It requires a custom plugin, which makes your Jekyll behavior non-standard
- All of your data files first need to be parsed by the Liquid parser before being parsed by YAML. This means there’s an extra level of parsing for errors to occur in.
- When errors do occur they are hard to track down. Do to the file-generation magic that the plugin performs, the line numbers reported by Psych are off. (On the other hand, even without this plugin Psych almost always returns the wrong line-numbers anyway).
- Data inclusion only goes one level deep.
You can reference
person.project, but notperson.project.persondue to the ifdef logic.
Still, I think these compromises are well worth the benefit for a large project. If this is something you’d like to experiment, you can grab the code directly from this gist.